This is the homepage of Peter Alexander. I am currently at Facebook working on AR/VR. Any opinions are my own.
Recent Posts
- Single-Threaded Parallelism
- unique_ptr Type Erasure
- The Condenser Part 1
- Cube Vertex Numbering
- Range-Based Graph Search in D
All Posts
Links
github.com/Poita@Poita_
Atom Feed
Single-Threaded Parallelism
Modern computers are able to go fast by doing many things at the same time. We often ask computers to do things at the same time by running code on different threads, but even on a single thread a computer is able to do a lot of things in parallel. One way it does this is by continuing to execute instructions while waiting for a memory access from a previous instruction to complete. This is called out of order execution.
Computers can only execute an instruction while waiting for a memory access if the instruction itself does not depend on the result of the memory access. For example, in C, loading a value through pointers such as a->b->c, we must first wait for the pointer a->b to be loaded before loading ->c. These cannot be loaded out of order, and this slows us down. Serialising memory accesses this way is called pointer chasing. It is a common source of performance issues.
How slow can it be? I wrote a benchmark that simulates pointer chasing by jumping around an array. The main loop is:
int k = 100_000_000;
size_t i = 0;
while (k--) {
i = a[i];
}The array a contains the integers 0 .. n, which are shuffled using Sattolo’s algorithm to contain a single cycle permutation. This ensures that every index of a is hit and that there’s no way for the computer to try and predict what memory to fetch next.
The benchmark will depend on the size of the array. Smaller arrays will fit in cache, where memory access latency is significantly smaller. I have run the benchmark for many different array sizes.
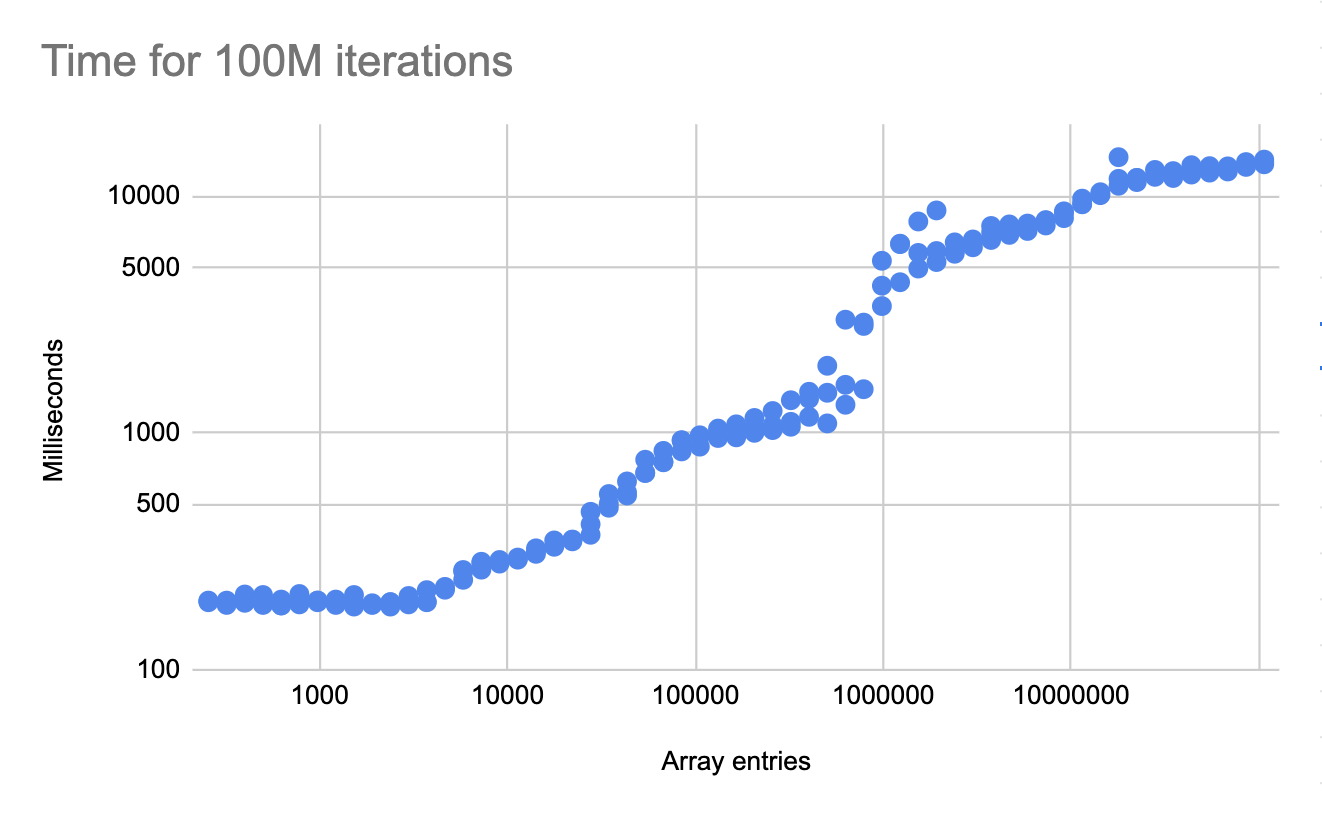
Note that in all runs we are doing 100M iterations of that array. The only difference between runs is the size of the array. The time to perform 100M iterations between the smallest array and largest is nearly 100x (both axes are logarithmic). Cache hit rates have a very significant affect on performance.
Is this task memory bound? At the right of the chart, the benchmark is running for around 14 seconds, each iteration is loading 64 bytes of memory (memory operates on cache lines rather than bytes). Putting this together, we are loading 6.4GB in 14 seconds, which is just over 450MB/s. Memory bandwidth is usually on the order of tens of gigabytes per second, so we are far from being memory bound.
The benchmark is slow because the memory accesses are serialised through pointer chasing. To go faster, we need to parallelise. We cannot parallelise this task without changing the underlying data structure, but we could run multiple of these tasks in parallel. We could use threads for this, but can we parallelise on a single thread? What if we iterated with two indices at the same time?
The next benchmark creates two permuted arrays (a and b) with the same combined size as the single array a from the previous benchmark. The iteration is then changed to:
int k = 100_000_000;
size_t i = 0;
size_t j = 0;
while (k--) {
i = a[i];
j = b[j];
}Note that we are still doing the same number of iterations, but with twice as many total lookups. How does this compare?
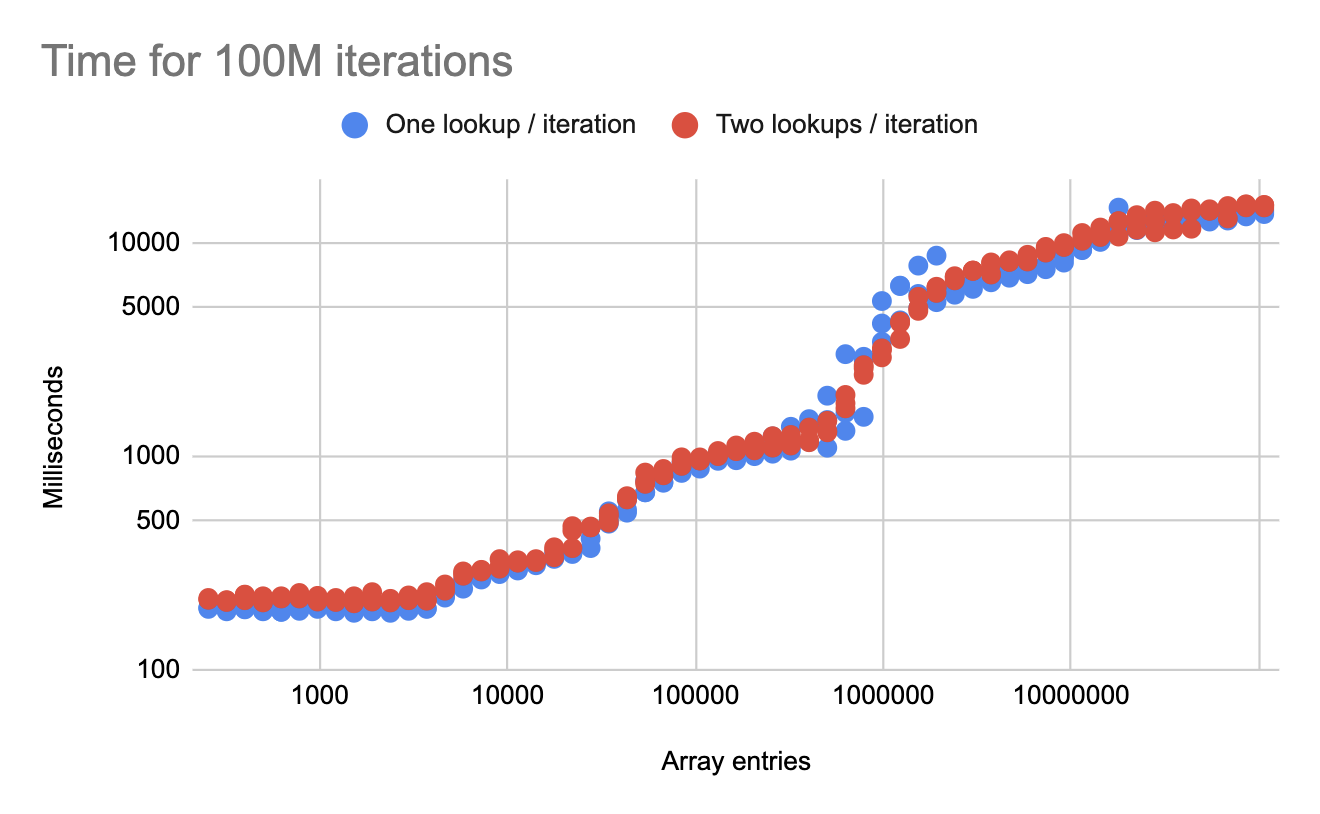
The times are very similar. On average, the second benchmark is less than 10% slower than the first benchmark, but is doing twice as much work! This scales because the memory loads from a and b can be done in parallel, even from a single thread.
We continue to see good scaling even with eight lookups per iteration.
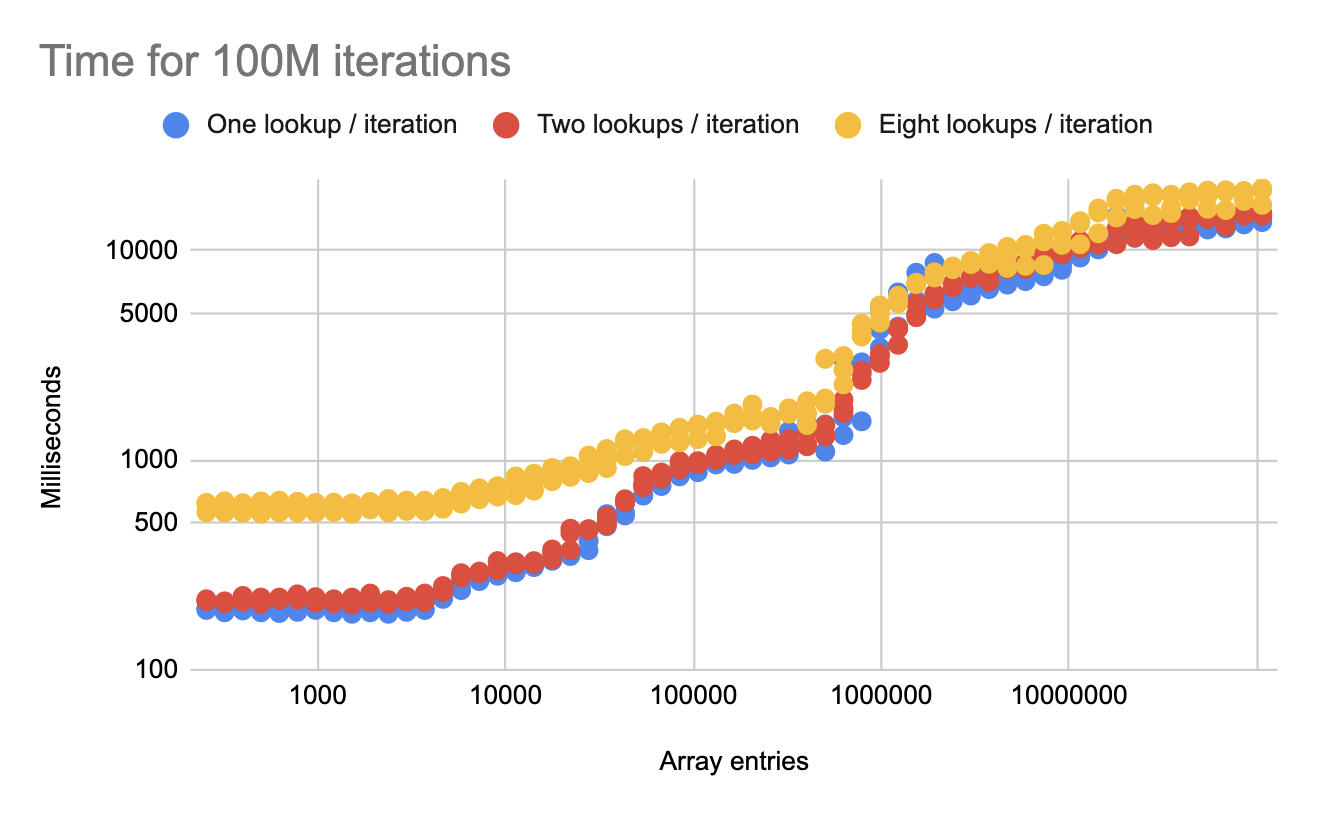
Amdahl’s Law is starting to kick in at smaller data sizes, but at larger sizes we still see significant gains from parallelism.
Memory access can have high latency, especially as the working set size of our programs increases. Computers try to compensate for memory latency by executing other instructions in parallel while waiting for memory accesses to complete, but they can only do this is there is other work that can be done without waiting. There are significant performance gains to be had by ensuring work is always available to be done, and the programmer plays a role in organising code so that this happens.